Ghidra Python Paleontology

TL;DR - This post will walk through the process of creating a Headless Ghidra Python VScode template. This is not recommended as the official language for Ghidra is Java and the supported IDE is Eclipse, but we will give it a go. The process involved “digging up” the Ghidra Python Scripting landscape and understanding what was possible. The lessons learned are capture in the VScode template ghidra-python-vscode-devcontainer-skeleton that alleviates the pain of getting setup with Ghidra Python scripting and leverages the power of devcontainers.
Excavating a Headless Ghidra Python Skeleton
Wanting to leverage some of the power of Ghidra FlatAPI, I started to dig into the methods of creating Ghidra Scripts. Ghidra is written in Java, and it’s scripting API is Java. It supports Python scripting via Jython (explored in detail below). This makes modern Python 3 development a bit more difficult. I set out to try to find a practical way to develop my Ghidra script in Python.
Ghidra Python Scripting Landscape
To understand where the current state of Python scripting with Ghidra, I started with a quick search to see what was out there. At the time I found the following and learned from each:
- Scripting Ghidra with Python by deadc0de6
- Ghidra’s FlatApi is powerful and available to Python
- Scripts can be edited and run within Ghidra’s Script Manager
- Experimenting with Ghidra Scripting by @pathtofile
- Python autocomplete exists for IDEs!
- Jython is how Ghidra provides Python scripting. It limits Python to 2.7.
- Python3 is possible!
- Ghidra Class Scripting
- Learn how to run scripts with the GUI
- Script development is done and officially supported in Eclipse
- A Guide to Ghidra Scripting Development for Malware Researchers by @marcofigueroa
- Ghidra has a basic script editor included
- Eclipse is the suggested and fully supported IDE by Ghidra.
From those articles, we begin to understand the possibilities (and limitations) of Python scripting with native Ghidra. Natively, Ghidra supports the use of Python via Jython (a reimplementation of Python in Java).
For developing Ghidra scripts, the obvious choice is clear:
When scripting with Ghidra, the logical choice for editing or creating scripts is the Eclipse IDE. A Guide to Ghidra Scripting Development for Malware Researchers
Ghidra prefers Java and recommends you use Eclipse.
 Thoughts on Java and Eclipse
Thoughts on Java and Eclipse
But! I want to use an IDE and language I’m familiar with. If you are reading this far, perhaps you are with me.
Existing VS Code Ghidra Scripting Template
Before we solve a problem that might be already solved, we take a look around for existing VScode templates. An experienced Ghidra developer atsrelky had a repo that seemed to be what I was looking for. It was a VScode template, vscode-ghidra-skeleton for Ghidra scripting. He had completed the work to integrate Java, but didn’t yet have support for Python.
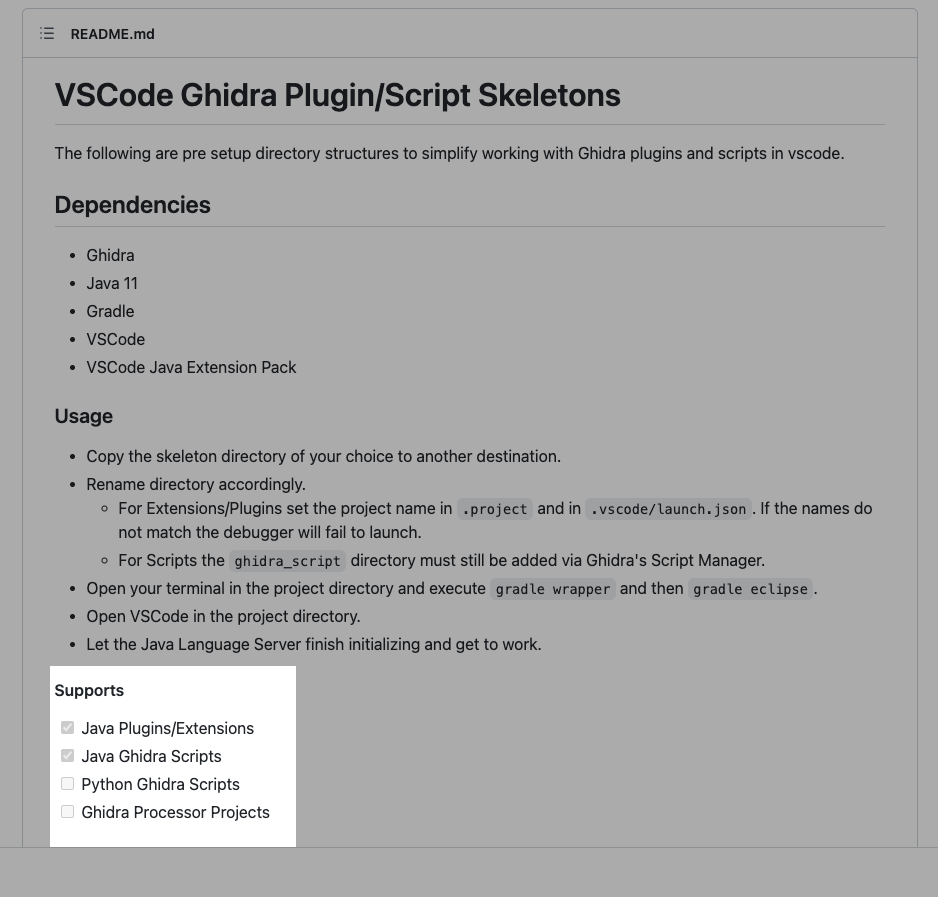 No Python Support
No Python Support
The template uses the skeleton scripts from Ghidra, supported auto-complete and inline debugging for Java Ghidra scripts via the vscode java extension pack. The VScode launch.json included contained the necessary VMARGs to help VScode run the scripts properly.
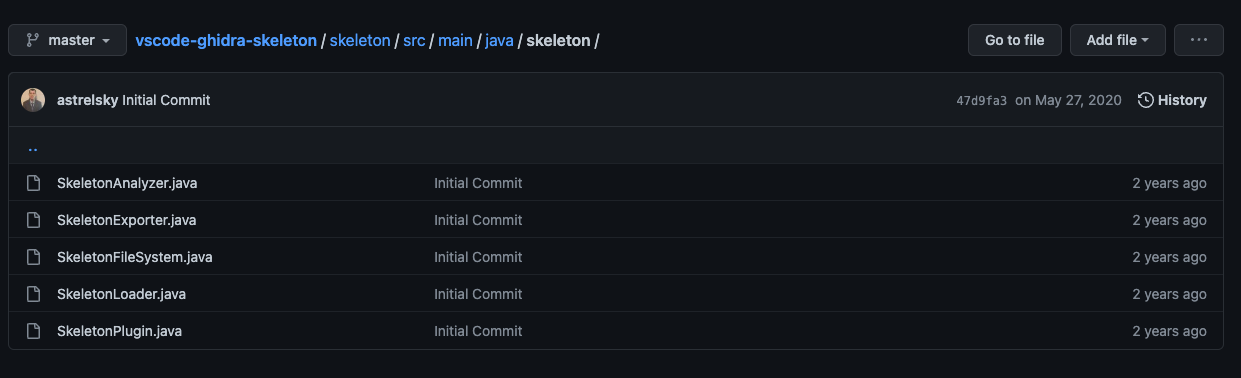 Skeleton Java Files
Skeleton Java Files
I didn’t see any other template examples on GitHub, but thanks to astrelsky I had inspiration.
The First Attempt - ghidra-python-vscode-skeleton v1
 ghidra-python-vscode-skeleton v1
ghidra-python-vscode-skeleton v1
To know how to build a Ghidra Python development environment, I had to understand the typical workflow for leveraging the Ghidra API and script. This is what I came up after understanding the standard instructions from Ghidra’s Headless Ghidra Scripting README.
Workflow
Quoted from the first version of the template ghidra-python-vscode-skeleton:
Ghidra is a binary analysis tool (and much more). In order to perform analysis via script, you first need to create a project and add binaries for analysis. Once a project exists with at least one binary added, headless analysis (scripting Ghidra) can begin.
Workflow Steps
This skeleton project prescribes a workflow and demonstrates various ways to run headless Ghidra Python scripts. The steps can be modified to suit your needs.
- Create Ghidra Project - Directory and collection of Ghidra project files and data
- Import Binary to project - Import one or more binaries to the project for analysis
- Analyze Binary - Ghidra will perform default binary analysis on each binary
- Run Ghidra Python script
These steps can be accomplished with the following two commands using Ghidra’s provided analyzeHeadless script.
- Import and create project
analyzeHeadless .ghidra_projects/sample_project sample_project -import /bin/ls
- Run a script
analyzeHeadless .ghidra_projects/sample_project sample_project -postscript sample.py
Running AnalyzeHeadless
The first iteration of the template did just that, provided the simple workflow. I created a project that you could clone, setup with pip with venv. It would run a python script using the prescribed method by running the analyzeHeadless script included with Ghidra with Python’s subprocess module.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
import os
import subprocess
# env vars from launch.json
ghidraHeadless = os.getenv('GHIDRA_HEADLESS')
projectPath = os.getenv('PROJECT_PATH')
projectName = os.getenv('PROJECT_NAME')
binary = os.path.basename(os.getenv('BINARY'))
script = os.getenv('HEADLESS_SCRIPT')
properties = script.split('.')[0] + '.properties'
properties_template = '''program={program}'''
# Arguments to pass to Ghidra
args = [ghidraHeadless, projectPath, projectName, "-postscript", script]
print(args)
with open(properties, 'w') as f:
f.write(properties_template.format(program=binary))
with open(properties, 'r') as f:
print(f.read())
subprocess.run(args)
The project assumed you had Ghidra installed, and you would update your settings.json to match your development environment. This file held some default arguments needed to analyze headless. The project supported autocomplete via VDOO-Connected-Trust/ghidra-pyi-generator.
Sample Ghidra Python Script
To demonstrate Ghidra’s FlatAPI, it would print section information for the binary with sample.py:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
prog = askProgram("program")
print("Program Info:")
program_name = prog.getName()
creation_date = prog.getCreationDate()
language_id = prog.getLanguageID()
compiler_spec_id = prog.getCompilerSpec().getCompilerSpecID()
print("Program: {}: {}_{} ({})\n".format(program_name, language_id, compiler_spec_id, creation_date))
# Get info about the current program's memory layout
print("Memory layout:")
print("Imagebase: " + hex(prog.getImageBase().getOffset()))
for block in prog.getMemory().getBlocks():
start = block.getStart().getOffset()
end = block.getEnd().getOffset()
print("{} [start: 0x{}, end: 0x{}]".format(block.getName(), start, end))
Shortcomings
The first iteration of the template project allowed you to run a python script and have autocomplete within your IDE. There were still several shortcomings with the template project, as it lacked:
- Debugging within the IDE - This version simply kicked off the [analyzeHeadless] script with no way to debug within the IDE.
- Python 3 support - This version relied on Ghidra’s Jyhon, which is limited to Python 2.7.
- Support for other platforms - The settings.json relied on a particular platform (in the first instance Windows) with hardcoded paths to python, but what if I wanted to develop on a different platform? When I tried the template on my Mac everything broke.
Evolving The Template - ghidra-python-vscode-devcontainer-skeleton v2
 ghidra-python-vscode-devcontainer-skeleton v2
ghidra-python-vscode-devcontainer-skeleton v2
For the next iteration of the template, I tried to explore others ways to run Python with Ghidra and support other platforms. I added the following examples to the new version of the template.
- run_headless.py - Jython using
subprocessandanalyzeHeadlessrunning sample.py - sample_bridge.py - Python 3 on the client, Jython running a RPC server.
- sample_pyhidra.py - Python 3 - CPython and Jpype
AnalyzeHeadless - Jython
The Jython project provides implementations of Python in Java, providing to Python the benefits of running on the JVM and access to classes written in Java. The current release (a Jython 2.7.x) only supports Python 2 (sorry). There is work towards a Python 3 in the project’s GitHub repository. Jython
This is Ghidra’s “native” support for Python. Jython is an implementation of the Python language in Java supporting up to Python 2.7. The Python 2.7 limitation is the primary reason the below projects exist. It is run within Ghidra’s Script Manager or the analyzeHeadless script as shown above. For IDE debugging, Eclipse is supported, but vscode-python has said no.
Ghidra Bridge - RPC server
 justfoxing/ghidra_bridge githhub
justfoxing/ghidra_bridge githhub
Ghidra Bridge brings Python 3 support, but still relies on Jython. It leverages jfx_bridge to link Python 2 and 3.
jfx_bridge is a simple, single file Python RPC bridge, designed to allow interacting from modern python3 to python2. It was built to operate in constrained interpreters, like the Jython interpreters built into more than one reverse-engineering tool, to allow you to access and interact with the data in the tool, and then use modern python and up-to-date packages to do your work. jfx_bridge
As far as I understand, it runs a Python RPC server via Ghidra’s Jython using jfx_bridge. First you need to run the Ghidra Bridge RPC server, then connect to it in your script.
Steps:
Then connect to the server and run the desired script. Code from sample_bridge.py:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
try:
proc = subprocess.Popen (args, shell=False, preexec_fn=os.setsid)
# Wait for ghidra_bridge_server to be ready
import time
while not is_port_in_use(BRIDGE_PORT):
time.sleep(1)
print("waiting for ghidra_bridge_server...")
with ghidra_bridge.GhidraBridge(namespace=globals(), response_timeout=4, ):
project = state.getProject()
projectData = project.getProjectData()
rootFolder = projectData.getRootFolder()
prog = askProgram("program")
print("Program Info:")
program_name = prog.getName()
creation_date = prog.getCreationDate()
language_id = prog.getLanguageID()
compiler_spec_id = prog.getCompilerSpec().getCompilerSpecID()
print("Program: {}: {}_{} ({})\n".format(program_name, language_id, compiler_spec_id, creation_date))
# Get info about the current program's memory layout
print("Memory layout:")
print("Imagebase: " + hex(prog.getImageBase().getOffset()))
for block in prog.getMemory().getBlocks():
start = block.getStart().getOffset()
end = block.getEnd().getOffset()
print("{} [start: 0x{}, end: 0x{}]".format(block.getName(), start, end))
# Give time for bridge connection to close
time.sleep(2)
As you can see in the code, the overhead is a bit high. For scripting, we need to first run the server, wait for it to be ready, connect to it within the context, and when I’m done I have to wait for the connection to close. Not only that, I found it incredibly slow.
Ghidra Bridge is an effort to sidestep that problem - instead of being stuck in Jython, set up an RPC proxy for Python objects, so we can call into Ghidra/Jython-land to get the data we need, then bring it back to a more up-to-date Python with all the packages you need to do your work. https://github.com/justfoxing/ghidra_bridge
For anything that is directly accessing data, it first has to run in Jython, then be brought back over RPC to your Python 3 client.
Despite being slow, it allows you to debug within VScode.
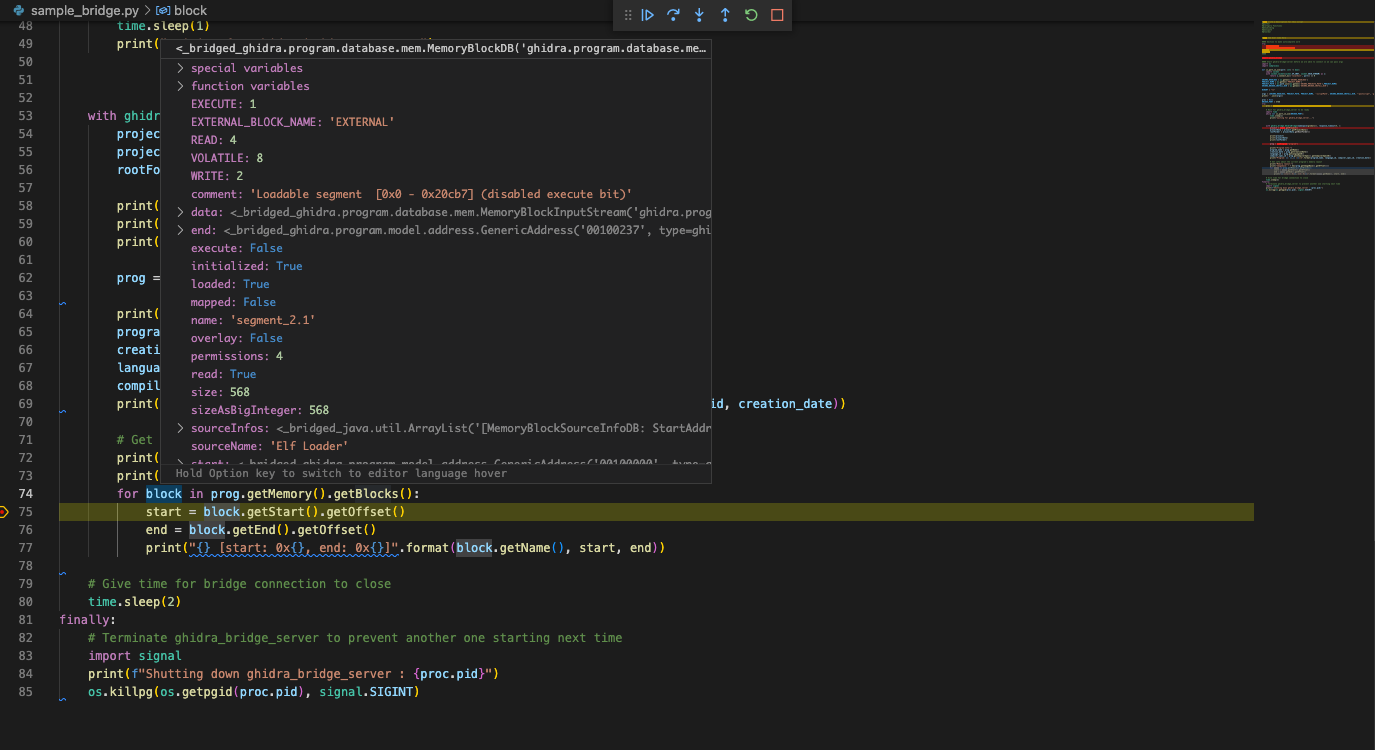 Ghidra Bridge IDE debugging
Ghidra Bridge IDE debugging
Pyhidra - CPython and Jpype
 Pyhidra Github
Pyhidra Github
Unlike Jython, JPype does not achieve this by re-implementing Python, but instead by interfacing both virtual machines at the native level. This shared memory based approach achieves good computing performance, while providing the access to the entirety of CPython and Java libraries. https://jpype.readthedocs.io/en/latest/
Pyhidra leverages CPython to interface with Java at the native level. No bridges or translation. It does this with Jpype. Full disclosure, this is my favorite Ghidra Python implementation so far. The Pyhidra library is clean and straightforward. The library installs a plugin to provide a Python 3 interpreter for Ghidra (so that it can be run in the GUI), or you can run your script with Python 3 (via JPype), without the need to modify Ghidra. The reason being is that JPype will start a JVM for you, load up Ghidra Java classes in its entirety, and provide you access to all the Ghidra Java classes from Python.
Taking a look inside Pyhidra we can see how it starts a JVM for its launcher.py:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
def start(self):
"""
Starts Jpype connection to Ghidra (if not already started).
"""
if not jpype.isJVMStarted():
if GHIDRA_INSTALL_DIR is None:
self._report_fatal_error(
"GHIDRA_INSTALL_DIR is not set",
textwrap.dedent("""\
Please set the GHIDRA_INSTALL_DIR environment variable
to the directory where Ghidra is installed
""").rstrip()
)
self.check_ghidra_version()
if self.java_home is None:
java_home = subprocess.check_output(_GET_JAVA_HOME, encoding="utf-8", shell=True)
self.java_home = Path(java_home.rstrip())
jvm = _get_libjvm_path(self.java_home)
jpype.startJVM(
str(jvm),
*self.vm_args,
ignoreUnrecognized=True,
convertStrings=True,
classpath=self.class_path
)
After it is initialized, you can then import classes and make direct calls to Ghidra. From sample_pyhidra.py:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
import pyhidra
pyhidra.start()
with pyhidra.open_program("/bin/ls") as flat_api:
prog = flat_api.getCurrentProgram()
print("Program Info:")
program_name = prog.getName()
creation_date = prog.getCreationDate()
language_id = prog.getLanguageID()
compiler_spec_id = prog.getCompilerSpec().getCompilerSpecID()
print("Program: {}: {}_{} ({})\n".format(program_name, language_id, compiler_spec_id, creation_date))
# Get info about the current program's memory layout
print("Memory layout:")
print("Imagebase: " + hex(prog.getImageBase().getOffset()))
for block in prog.getMemory().getBlocks():
start = block.getStart().getOffset()
end = block.getEnd().getOffset()
print("{} [start: 0x{}, end: 0x{}]".format(block.getName(), start, end))
As you have a direct connection to the JVM, you can debug it natively with VScode:
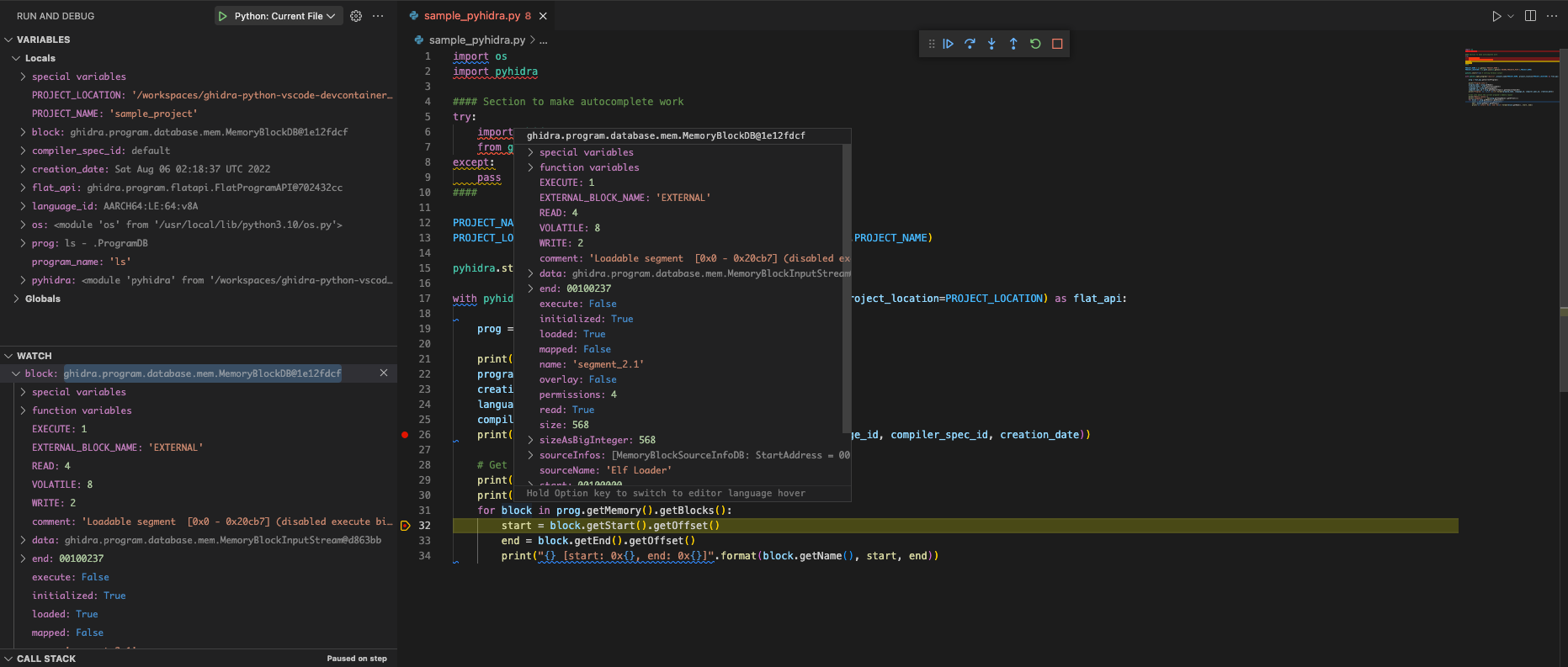 Pyhidra Debug
Pyhidra Debug
When I script something new now, I use Pyhidra. It relies on Jpype, which isn’t perfect and I was able to find a fix another issue with conflicting module names, but I have to say it is the best I have found so far for Ghidra Python scripts.
Ghidrathon and Jep
 Ghidrathon Github
Ghidrathon Github
Ghidrathon is a Ghidra extension that adds Python 3 scripting capabilities to Ghidra… Ghidrathon replaces the existing Python 2 extension implemented via Jython. This includes the interactive interpreter window, integration with the Ghidra Script Manager, and script execution in Ghidra headless mode. ghidrathon
Ghidrathon came out while I was creating this template, and I can’t see any benefit this library brings over Pyhidra and Jpype. It similarly provides Python 3 support, like bridge of Pyhidra, but it doesn’t support in IDE debugging for VScode. It acts more like Jython interpreter running the scripts (albeit Python 3).
Jep stands for Java embedded Python. It is a mirror image of JPype. Rather that focusing on accessing Java from within Python, this project is geared towards allowing Java to access Python as sub-interpreter. The syntax for accessing Java resources from within the embedded Python is quite similar with support for imports. Jpype Docs
Perhaps I am missing something, but I can’t see all the hype. It also seems to have issues with threading? I didn’t see an easy way to integrate it into my template, or make it work for VScode besides a subprocess example like AnalyzeHeadless.
Devcontainers
Leveraging one of the ways to run Python options above, you can have Python debugging in VScode, autocomplete, or both. The last problem to solve to allow the template to work on all platforms. I couldn’t see a way to do this without providing 1000 settings.json configurations and launch.json and tasks.json variations. Instead, I went down the path of containers to solve it for me.
Devcontainers (docker containers) within VScode allow you to define and ensure your development environment despite your platform. This is really powerful when you are trying to create a template that behaves the same anywhere. If you haven’t tried developing inside a container with vscode, you should.
“One of the useful things about developing in a container is that you can use specific versions of dependencies that your application needs without impacting your local development environment. “ Get started with development Containers in Visual Studio Code
“This lets VS Code provide a local-quality development experience including full IntelliSense (completions), code navigation, and debugging regardless of where your tools (or code) are located.” Developing inside a Container using Visual Studio Code Remote Development
Here is a quick list of how I leveraged devcontainers:
- Created a .devcontainer folder to clearly define the development environment.
- Based container image off of standard python3 dev container
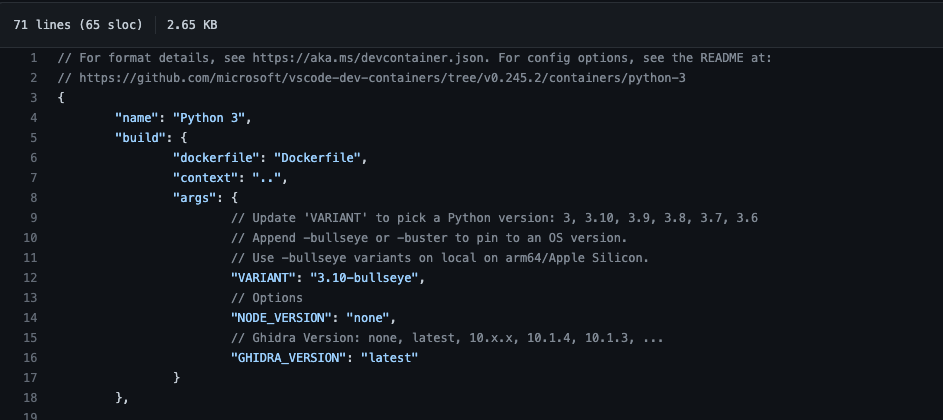
- Built a feature script to download the latest ghidra - ghidra-install.sh
- Python Virtual Environment auto setup via post-create command in devcontainter.json
And the result is pretty smooth. 
Conclusion
In summary, you now have ghidra-python-vscode-devcontainer-skeleton. A self-proclaimed amazing template for Python script development with the Ghidra scripting API. To get started, check out the Quick Start
Square Peg Round Hole?
Ghidra is written in Java and provides development support for Eclipse. Perhaps Python and VScode shouldn’t even be considered. Admittedly, it was my inexperience with Java and Eclipse that drove me down this path. I blame Ghidra. With Jython integrated, Ghidra Python scripting was just accessible enough to make me push through the pain of creating this template. That being the case, this exercise taught me quite a bit about Python and Java bridges, pipes, and devcontainers. Hopefully, you as well.
Summary Table
| Problems (invented or otherwise) | Solutions |
|---|---|
| Java | Python |
| Eclipse | VScode |
| Developing Ghidra Python Scripts | ghidra-python-vscode-devcontainer-skeleton |
| Autocomplete for Python scripts | ghidra-pyi-generator |
| Python Debugging in VSCode | pyhdira |
| Python 3 support | ghidra-bridge or pyhdira maybe even ghidrathon |
| Standardizing the development environment | Devcontainers |
Please reach out @clearbluejar with questions or comments. Also appreciate any feedback or corrections you might have for the post.