System Over Model, Tested: Reproducing Mythos's FreeBSD Find on Local Open-Weight Models

TL;DR Anthropic’s Claude Mythos Preview in April 2026 showed a frontier model finding CVE-2026-4747, a 17-year-old RCE in FreeBSD’s RPCSEC_GSS authentication. A week later, Stanislav Fort at AISLE published a counter-thesis and reproduced the same find with
gpt-5.4-nanousing their publishednano-analyzerpipeline for under $100. I wanted to see whether that reproduction works further down the cost curve. So I ran the pipeline at full sub-system scope (~50 files) using two open-weight models,openai/gpt-oss-20bandgoogle/gemma-4-31b-it. Out of the box it looked like both missed. But a re-run makes the “miss” go away, and the model finds the bug. The real problem with the local models is noise: the pipeline graduates a pile of false positives and buries the real one. So I changed the system, not the model. One extra reachability stage drops the false positives from 30 to 5, the CVE still standing. The scaffolding does the work, and it’s a lever you can pull on your own model.
The Mythos preview was the moment “AI finds zero-days” stopped being theoretical or at least when everyone started paying attention. AISLE’s reply reminded us that finding zero-days wasn’t a frontier-only capability. Fort’s post reproduced the same discovery on a non-frontier model, using an LLM-powered Python scanner explained below. The system, he argued, is doing more of the work than the model. The scaffolding is key: prompts, pipeline shape, triage rounds.
I like the AISLE post. I run local models for several of my RE projects, and they’re getting good fast. The bet that scaffolding does more of the work than the model matched what I was seeing (not that Mythos isn’t strong, but I was surprised how much the system is still needed). So the question I cared about was simple: same pipeline, same CVE, but on an open-weight model I can run myself.
This post is about that test. Out of the box, at full sys/rpc/ sub-system scope, the pipeline looked like it missed CVE-2026-4747 on both models. What I got wrong was my first read of why.
What AISLE Claimed, and What I Tested
AISLE’s published reproduction surfaced CVE-2026-4747 with gpt-5.4-nano (default, 2-of-3 trials) and reported GPT-OSS-20B at 2-of-3 in their table.
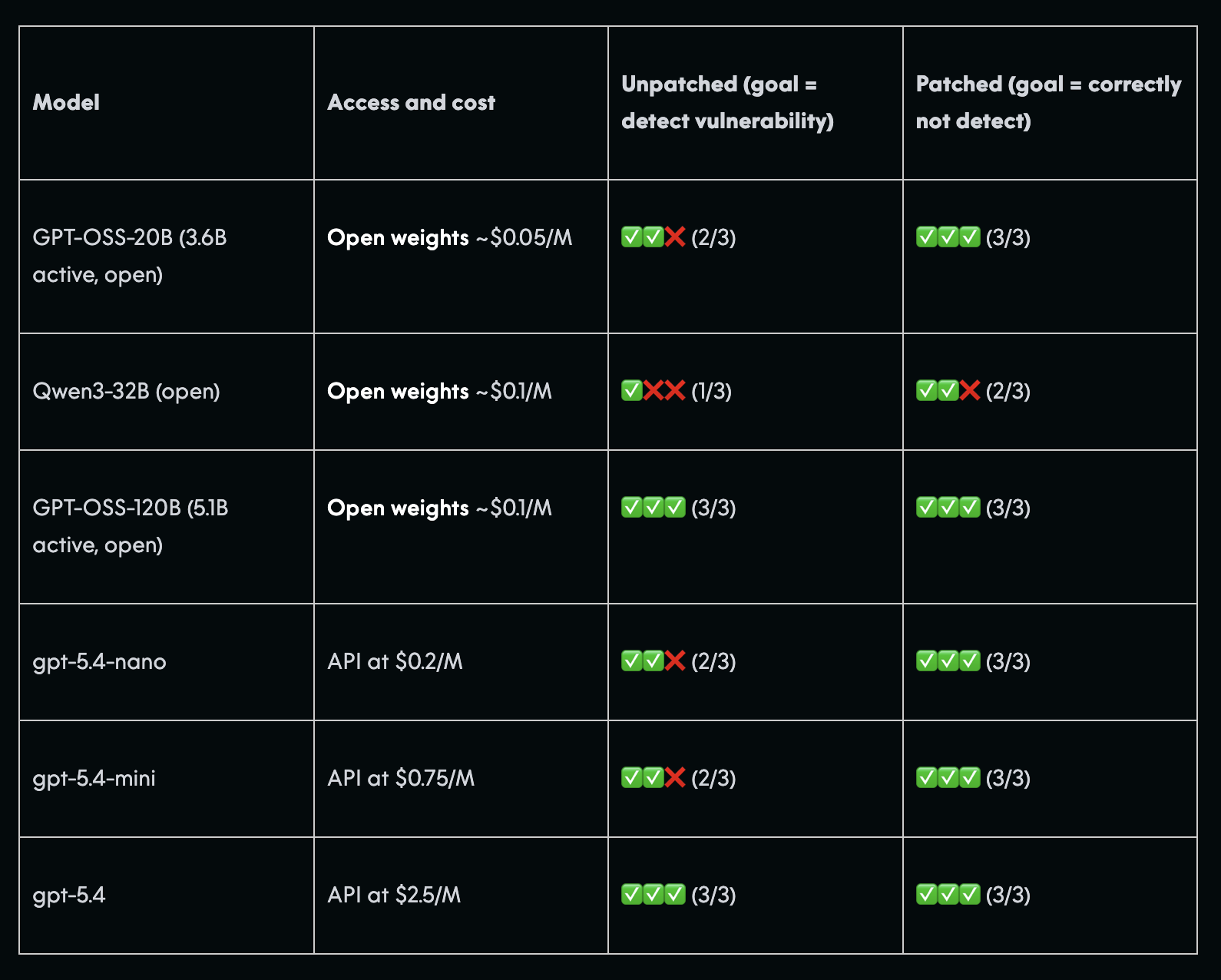 AISLE’s published benchmark for CVE-2026-4747, detect it in the unpatched tree, stay quiet on the patched one. AISLE doesn’t state the scope per model, which is the gap this post digs into.
AISLE’s published benchmark for CVE-2026-4747, detect it in the unpatched tree, stay quiet on the patched one. AISLE doesn’t state the scope per model, which is the gap this post digs into.
Their scanner, 1,700 lines of Python, is the three-stage shape several recent AI-vulnscan pipelines use. AISLE’s scan.py runs each file through it:
- Context briefing (
<file>.context.md): map the file’s attack surface (untrusted inputs, buffer sizes, data flows), no bug-hunting yet. - Scan and report severity (
<file>.md+<file>.json): a worked example (few shot) plus five analytical questions, the model returns severity-rated candidates. - Triage (
triages/, thenfindings/): candidates at medium severity or higher get re-checked across several rounds, then a separate-model arbiter (with a grep lookup) decides what graduates.
flowchart TD
Dir[("Directory: sys/rpc/")]
Dir --> F1[auth_unix.c]
Dir --> F2[svc_rpcsec_gss.c]
Dir --> F3[clnt_dg.c]
Dir --> Fn["...50 files in parallel"]
F1 --> S1
F2 --> S1
F3 --> S1
Fn --> S1
S1["<b>Stage 1: Context briefing</b><br/>per file"] --> S2
S2["<b>Stage 2: Vulnerability scan</b><br/>5 analytical questions +<br/>3-bug few-shot example"] --> Cand
Cand[("Candidates<br/>severity-rated")] --> Gate
Gate{"severity ≥ medium?"}
Gate -->|no| Drop1[/"dropped pre-triage"/]
Gate -->|yes| T["<b>Stage 3: Multi-round triage</b>"]
T --> R1["Round 1<br/>V / U / I"]
R1 --> R2["Round 2<br/>V / U / I"]
R2 --> Rn["Round N<br/>V / U / I"]
Rn --> Vote{"Majority?"}
Vote -->|≥2 VALID| Surv[("graduated to findings")]
Vote -->|≥2 INVALID| Drop2[/"filtered out"/]
Vote -->|tie / UNCERTAIN| Arb["Arbiter<br/>different model<br/>+ grep verification"]
Arb -->|VALID| Surv
Arb -->|INVALID / UNCERTAIN| Drop2
classDef stage fill:#e8f0ff,stroke:#333,stroke-width:1px,color:#1a1a1a
classDef round fill:#e6f0ff,stroke:#666,color:#1a1a1a
classDef file fill:#f5f5f5,stroke:#999,color:#1a1a1a
classDef terminal fill:#f0f0f0,stroke:#333,stroke-width:2px,color:#1a1a1a
classDef gate fill:#fff5e6,stroke:#cc8800,stroke-width:1px,color:#1a1a1a
classDef survive fill:#d4edda,stroke:#155724,color:#1a1a1a
classDef drop fill:#f8d7da,stroke:#721c24,color:#1a1a1a
class Dir terminal
class F1,F2,F3,Fn file
class S1,S2,T,Arb stage
class R1,R2,Rn round
class Gate,Vote gate
class Surv survive
class Drop1,Drop2 drop
This scanner is basic: a handful of LLM-powered rounds over every file, no clever targeting. It brute-forces where a frontier model would reason strategically about where to look, and it works with surprising success. So I tested it at the scope a real hunt would use, on local open-weight models, trying to answer the question: does AISLE’s pipeline still find the bug?
The two models:
openai/gpt-oss-20b: open-weight, 20 billion parameters, runs on a single consumer GPU. Same model AISLE listed. Ancient model in “AI time”, but one of the first local models that gave me real results.google/gemma-4-31b-it: open-weight, 31 billion parameters, same single consumer GPU. Not in AISLE’s table; I’ve been meaning to test it more for RE/VR.
Here’s the bug, svc_rpc_gss_validate in svc_rpcsec_gss.c:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
/* struct opaque_auth, from sys/rpc/xdr.h */
struct opaque_auth {
enum_t oa_flavor; /* flavor of auth */
caddr_t oa_base; /* address of more auth stuff */
u_int oa_length; /* not to exceed MAX_AUTH_BYTES */
};
/* FreeBSD sys/rpc/rpcsec_gss/svc_rpcsec_gss.c (pre-patch) */
static bool_t
svc_rpc_gss_validate(struct svc_rpc_gss_client *client, struct rpc_msg *msg,
gss_qop_t *qop, rpc_gss_proc_t gcproc)
{
struct opaque_auth *oa;
gss_buffer_desc rpcbuf, checksum;
OM_uint32 maj_stat, min_stat;
gss_qop_t qop_state;
int32_t rpchdr[128 / sizeof(int32_t)];
int32_t *buf;
memset(rpchdr, 0, sizeof(rpchdr));
/* Reconstruct RPC header for signing (from xdr_callmsg). */
buf = rpchdr;
IXDR_PUT_LONG(buf, msg->rm_xid);
IXDR_PUT_ENUM(buf, msg->rm_direction);
IXDR_PUT_LONG(buf, msg->rm_call.cb_rpcvers);
IXDR_PUT_LONG(buf, msg->rm_call.cb_prog);
IXDR_PUT_LONG(buf, msg->rm_call.cb_vers);
IXDR_PUT_LONG(buf, msg->rm_call.cb_proc);
oa = &msg->rm_call.cb_cred;
IXDR_PUT_ENUM(buf, oa->oa_flavor);
IXDR_PUT_LONG(buf, oa->oa_length);
/* No upper bound, only a non-zero check: attacker-controlled
* oa_length (a u_int) overruns the 96 bytes left in the 128-byte rpchdr. */
if (oa->oa_length) {
memcpy((caddr_t)buf, oa->oa_base, oa->oa_length);
buf += RNDUP(oa->oa_length) / sizeof(int32_t);
}
<several lines omitted>
}
On the vulnerable file by itself, both models nail it. Scan just svc_rpcsec_gss.c and each confirms the overflow.
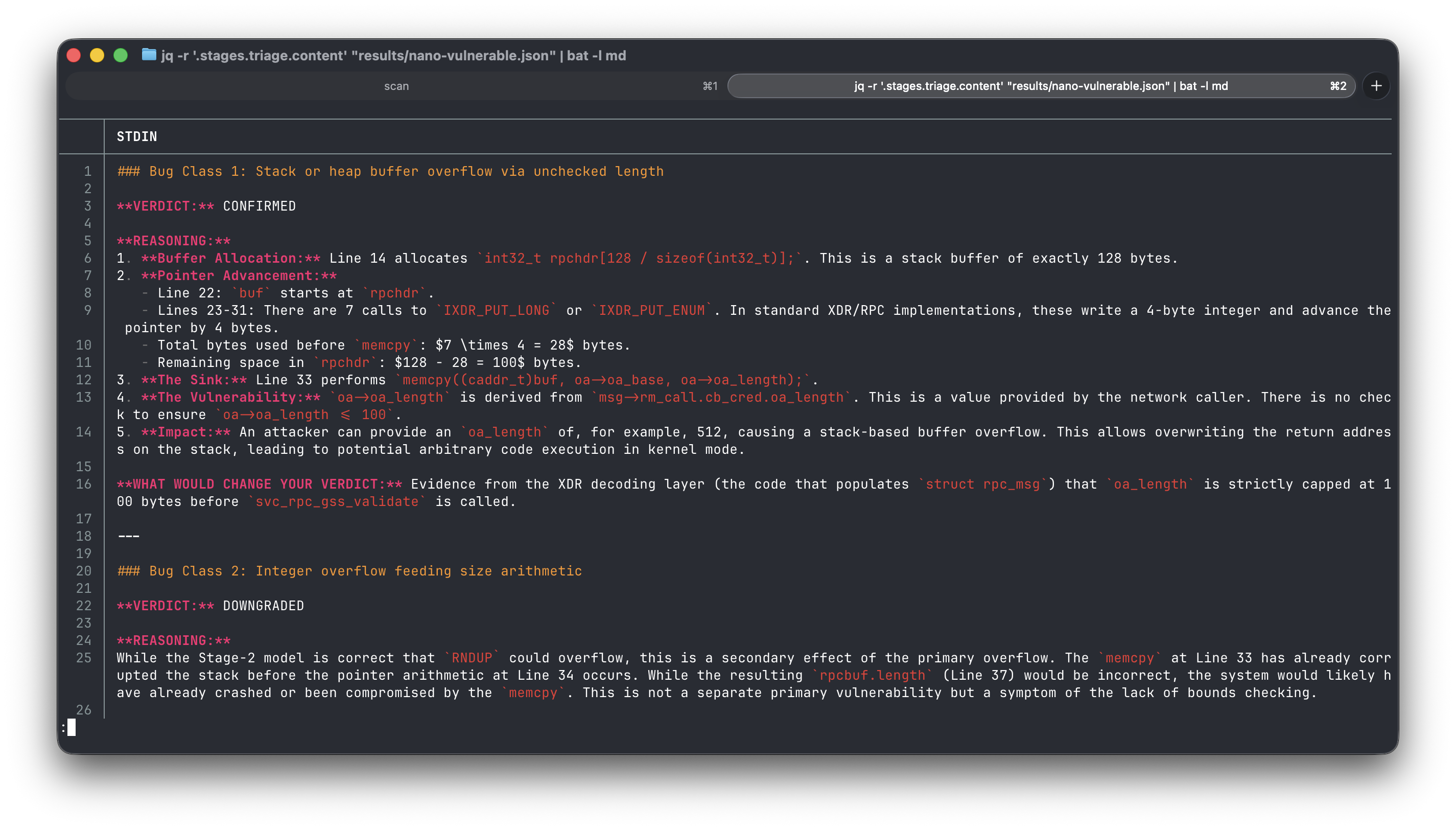
The code copies
oa->oa_lengthbytes into a 128-byte stack buffer (rpchdr) without any bounds check.oa->oa_lengthcomes from the network and can be arbitrarily large or negative, so the copy can overflow the stack and corrupt control data.
The code copies
oa->oa_lengthbytes into a 128-byte stack buffer that already contains 32 bytes of header. No bounds check is performed before thememcpy. If the credential length exceeds 96 bytes the copy overruns the buffer.
That’s the easy case, and it matches AISLE’s focused detection: eight of eight models in their jagged-frontier post caught this bug.
But a single file isn’t a real test, and it isn’t what Mythos did. Per Anthropic’s writeup, Mythos scaffolded across hundreds of kernel files: rank each by attack surface, hypothesize, run the project to confirm or reject, validate against a crash oracle. Even the frontier model leaned on the system.
So I ran that same scaffold type on these local models, scaled up from the single file to the whole freebsd-prepatch/sys/rpc/ sub-system, ~50 files and 20,000 lines, what you might target searching for RPC bugs.
I ran AISLE’s scan.py as published, multi-round triage and grep-backed arbiter, on each model. One pipeline, two models, one target, CVE-2026-4747. The question was simple: does it find the bug, and can you trust what it reports?
Run 1 — AISLE’s Pipeline + gemma-4-31b-it: Right Line, Wrong Rationale
flowchart LR
A[("~50 files<br/>sys/rpc/")] --> S["scan"]
S --> C[("157 candidates")]
C --> T["triage<br/>3 rounds + arbiter"]
T --> V[("30 VALID findings")]
S -.->|"CVE-2026-4747 written up, not scored"| X[/"dropped at scan"/]
classDef node fill:#e8f0ff,stroke:#333,color:#1a1a1a
classDef drop fill:#f8d7da,stroke:#721c24,color:#1a1a1a
class A,S,C,T,V node
class X drop
Run 1’s funnel. The 17-year-old RCE never reaches the 157 candidates, Gemma downgrades it at scan, so the triage rounds never see it.
AISLE’s scan.py against sys/rpc/ on gemma-4-31b-it ran for ~60 minutes. The funnel surfaces 157 candidates at scan stage (anything that might be a bug) and after three rounds of triage 30 graduate to VALID findings. CVE-2026-4747 is not among them. The scan stage flags svc_rpc_gss_validate, but it reasons about the bug incorrectly.
Gemma’s scan claims a bounds check the code doesn’t have:
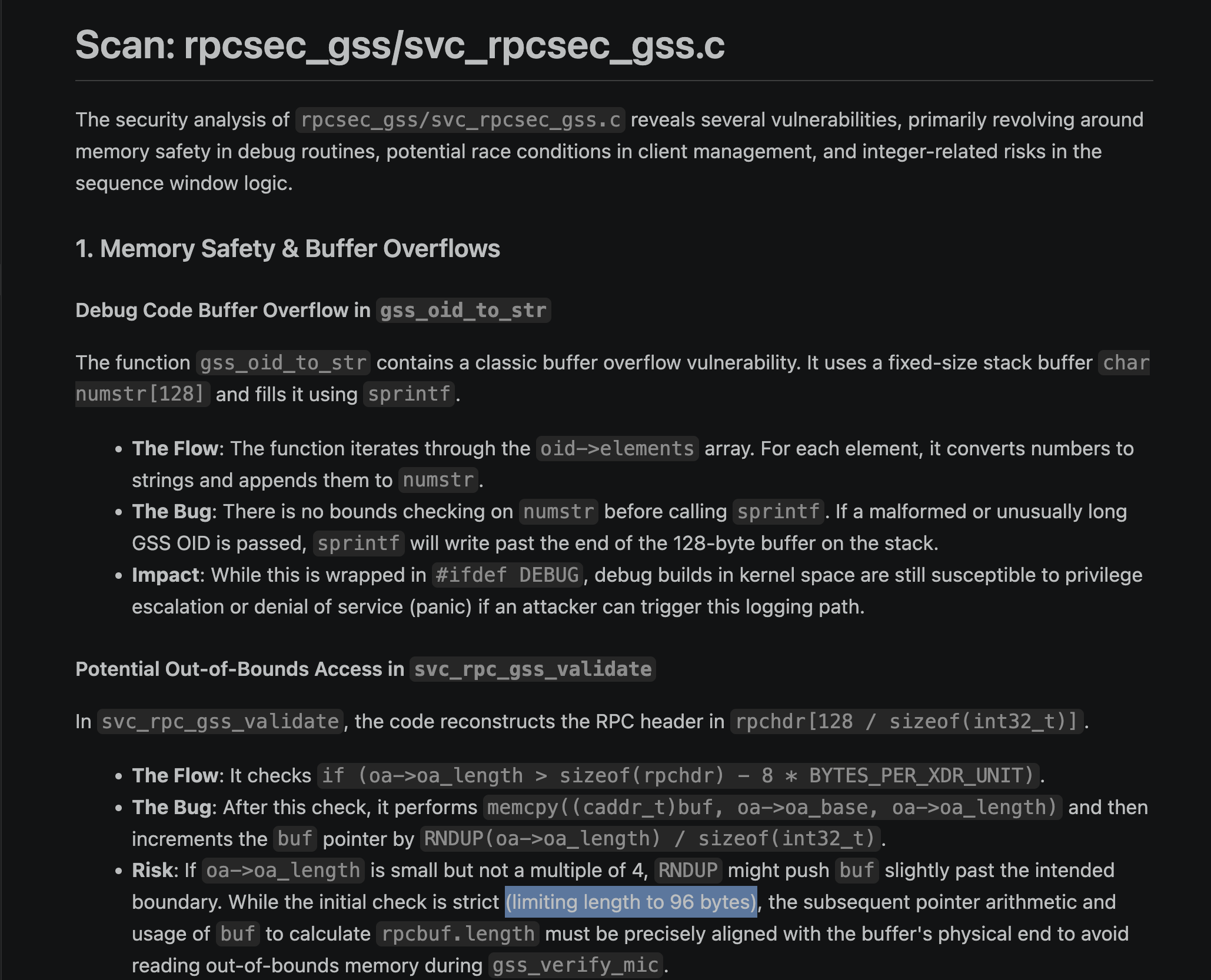
But the code has no such check, only if (oa->oa_length), a non-zero test. Gemma invented a defense that isn’t in the code, downgraded the real overflow to a minor RNDUP alignment issue, and dropped it before triage ever saw it. The scan digest for that file shows the cost: svc_rpcsec_gss.c comes back with zero critical findings.
The run died at the scan stage. A 31-billion-parameter model had talked itself out of a textbook stack overflow, and my honest first read was that Gemma just wasn’t up to the real thing. Hold that thought.
Run 2 — AISLE’s Pipeline + gpt-oss-20b: Right Answer, Dropped by the Vote
flowchart LR
A[("~50 files<br/>sys/rpc/")] --> S["scan"]
S --> C[("173 candidates")]
C --> T["triage<br/>3 rounds + arbiter"]
T --> V[("21 VALID findings")]
T -.->|"CVE-2026-4747 voted U / V / U"| X[/"47 UNCERTAIN, dropped"/]
classDef node fill:#e8f0ff,stroke:#333,color:#1a1a1a
classDef drop fill:#f8d7da,stroke:#721c24,color:#1a1a1a
class A,S,C,T,V node
class X drop
Run 2’s funnel. This time the RCE reaches triage and gets scored, but the three rounds split U / V / U, normalize to UNCERTAIN, and it drops into the 47-deep UNCERTAIN pile below the graduation threshold.
Same scan.py, same sys/rpc/ scope, on openai/gpt-oss-20b and another hour scan time. The funnel surfaces 173 candidates at scan stage, 21 graduate to VALID, and 47 land in UNCERTAIN (the pile that didn’t clearly pass or fail).
CVE-2026-4747 is in the UNCERTAIN pile. Look at the per-round triage trace for that candidate:
Round 1: ❓ UNCERTAIN
Round 2: ✅ VALID
“Overflow due to memcpy of unbounded
oa->oa_lengthinto a 128‑byte stack buffer rpchdr in svc_rpc_gss_validate. The code does not limit oa_length – only checks that it is non‑zero. An attacker controls oa_length via the network packet’s rpc_cred field, and can set it arbitrarily large. No defensive check (e.g., bound on oa_len, MAXAUTH, or RPC message size) is performed before this call. Therefore the overflow is reachable and can corrupt the stack, leading to possible crash or code execution.”Round 3: ❓ UNCERTAIN
The model is capable of the right answer in round 2, just not reliably. Rounds 1 and 3 went the other way, the vote landed on UNCERTAIN at 33% confidence, and the funnel dropped it. The pipeline didn’t fail because the model was wrong. It failed because the model only looked right one time out of three. Both AISLE’s published numbers (gpt-5.4-nano and gpt-oss-20b each at 2 of 3 trials on the same CVE) and ours land at the same observation. With this model, the triage verdict is a coin flip.
The Misses Don’t Survive a Second Look
Walk away after Run 1 and Run 2 and you’d say “the models just aren’t up to it.” That was my first thought too. But you should always run a test twice.
Re-run Gemma’s scan on svc_rpcsec_gss.c and it catches the overflow, not once but every time: twelve hosted runs and five more on a local 4-bit quant, seventeen for seventeen, each reporting that nothing bounds oa_length before the memcpy. Here’s one of those runs: same pipeline, same file, the overflow back at #1. Run 1’s confident miss was the exception, one unlucky draw out of eighteen. gpt-oss is shakier, but the same issue. Run its triage several more times and the finding survives in eleven of fourteen tries.
The vulnerable-vs-patched check in AISLE’s table up top holds on local models too: hand the pair to five local models with no hints, and four of five tell them apart.
| Model | Vulnerable | Patched twin | Tells them apart? |
|---|---|---|---|
gpt-oss-20b | flagged | rejected | ✅ |
qwen3.5-35b | flagged | rejected | ✅ |
qwen3.5-35b (/no_think) | flagged | rejected | ✅ |
gemma-4-26b (abliterated) | flagged | rejected | ✅ |
gemma-4-31b | flagged | “confirmed” (false positive) | ❌ |
The lone miss, gemma-4-31b, false-positives on the patch in this run; re-run it and it clears the patch six of six, the same single-run noise the rest of the post is about. Full matrix and per-model output.
The Real Problem Is the False Positives
The misses recover after running more than once. The noise doesn’t.
Run 1 graduated 30 findings to VALID. I read all thirty against the source. Exactly one was a real defect, and it wasn’t CVE-2026-4747: it was an unrelated, still-unfixed double-rw_wlock deadlock in clnt_nl_destroy that the funnel surfaced by accident. The bug I wanted to find never made the list. Run 2 graduated 21, same story. The funnel feels productive, and it’s mostly noise burying the one finding that matters.
That’s the real cost of running these models out of the box. Not that they can’t find the bug, but without help from the system they struggle to find the signal in the noise.
Change the System, Not the Model
The false positives aren’t necessarily a model failure. The system just isn’t doing enough for these models yet. It graduates anything shaped like a bug without asking whether an attacker can actually reach it.
So I gave it one more stage. Same weights, no new model. A reachability pass that takes each VALID finding and makes the model trace it back to an entry point, grep for the callers, check whether the cited length is really attacker-controlled or just kernel-set, and reject anything that’s dead code or already bounded. On Run 1’s thirty, it keeps five and drops twenty-five. And it doesn’t throw away the real bug: feed it the surfaced CVE finding and the filter keeps it VALID, five runs out of five.
flowchart LR
V[("AISLE funnel<br/>30 VALID findings")] --> R["reachability stage<br/>same weights, +1 pass<br/>is it attacker-reachable?"]
R --> K[("5 VALID<br/>includes the CVE, valid across 5 runs")]
R -.->|"not reachable: dead code, kernel-set length, privileged-only"| D[/"25 dropped"/]
classDef node fill:#e8f0ff,stroke:#333,color:#1a1a1a
classDef keep fill:#d4edda,stroke:#155724,color:#1a1a1a
classDef drop fill:#f8d7da,stroke:#721c24,color:#1a1a1a
class V,R node
class K keep
class D drop
Five isn’t zero false positives though, the survivors are “reachable but bounded” cases you still check by hand. But five is a list you’ll actually read, while thirty is where the real one gets lost.
And it isn’t a Gemma trick. The same stage prunes gpt-oss’s findings the same way, CVE kept, down from 21 to 4 VALID. Same lever AISLE pulled: improve the system, not the model. It’s one stage, reachability_filter.py in the repo, and you can try it on your own runs.
Reproduce It Yourself
Everything’s in clearseclabs/system-over-model-gemma, Apache 2.0, attribution to AISLE upstream. Point any OpenAI-compatible endpoint at it (LM Studio, Ollama, vLLM, OpenWebUI, OpenRouter), set LM_BASE_URL and LM_API_KEY, and bring whatever model you can run. The repo has:
scaffolding/reachability_filter.py: the reachability stage, run it on any scanner’sfindings/to cut the false positivesscaffolding/fetch_freebsd.sh: shallow-clones the pre-patch (vulnerable) FreeBSDsys/rpc/tree- The cached AISLE runs,
results-aisle-gemma-sysrpc/(Run 1) andresults-aisle-gpt-oss-sysrpc/(Run 2), with per-file context, scan,triages/, and the graduatedfindings/ run1-reproducibility/andrun2-reproducibility/: the re-runs that turn each “miss” into a rate, plus the triage and local-quant checksreachability-tweak/: the 30→5 result and the keep-the-CVE test5-model-matrix/: five local models on the vulnerable-vs-patched pair
AISLE’s scan.py itself (~1,700 LoC, multi-round triage with grep-as-tool) is upstream at weareaisle/nano-analyzer.
To run it end to end on your own model:
- Get the target.
scaffolding/fetch_freebsd.shshallow-clones the pre-patch (vulnerable)sys/rpc/tree intofreebsd-prepatch/. - Scan it with your backend. Copy
.env.exampleto.envwith your endpoint, clone AISLE’sscan.pyalongside the repo, then therun-aisle.shwrapper runs the real 3-stage scan on a single file:scan-demo/bin/run-aisle.sh targets/vulnerable.c(~5–10 min). It derives AISLE’sCUSTOM_BASE_URL/CUSTOM_API_KEYfrom your.envfor you. Point the samescan.pyatfreebsd-prepatch/sys/rpcfor the full sub-system run. - Cut the noise. Point
reachability_filter.pyat the run’sfindings/. The cachedresults-aisle-*-sysrpc/show what a full pass oversys/rpc/produces if you’d rather not re-scan. - Or in one shot.
scan-and-filter.shchains steps 2 and 3. Hand it one file (scan-demo/bin/scan-and-filter.sh targets/vulnerable.c) or the whole tree for the full sub-system run (scan-demo/bin/scan-and-filter.sh freebsd-prepatch/sys/rpc); it scans, runs the reachability stage, and copies the survivors intofindings-reachable/. Use--filter-only <findings/>to re-filter a run you already have.
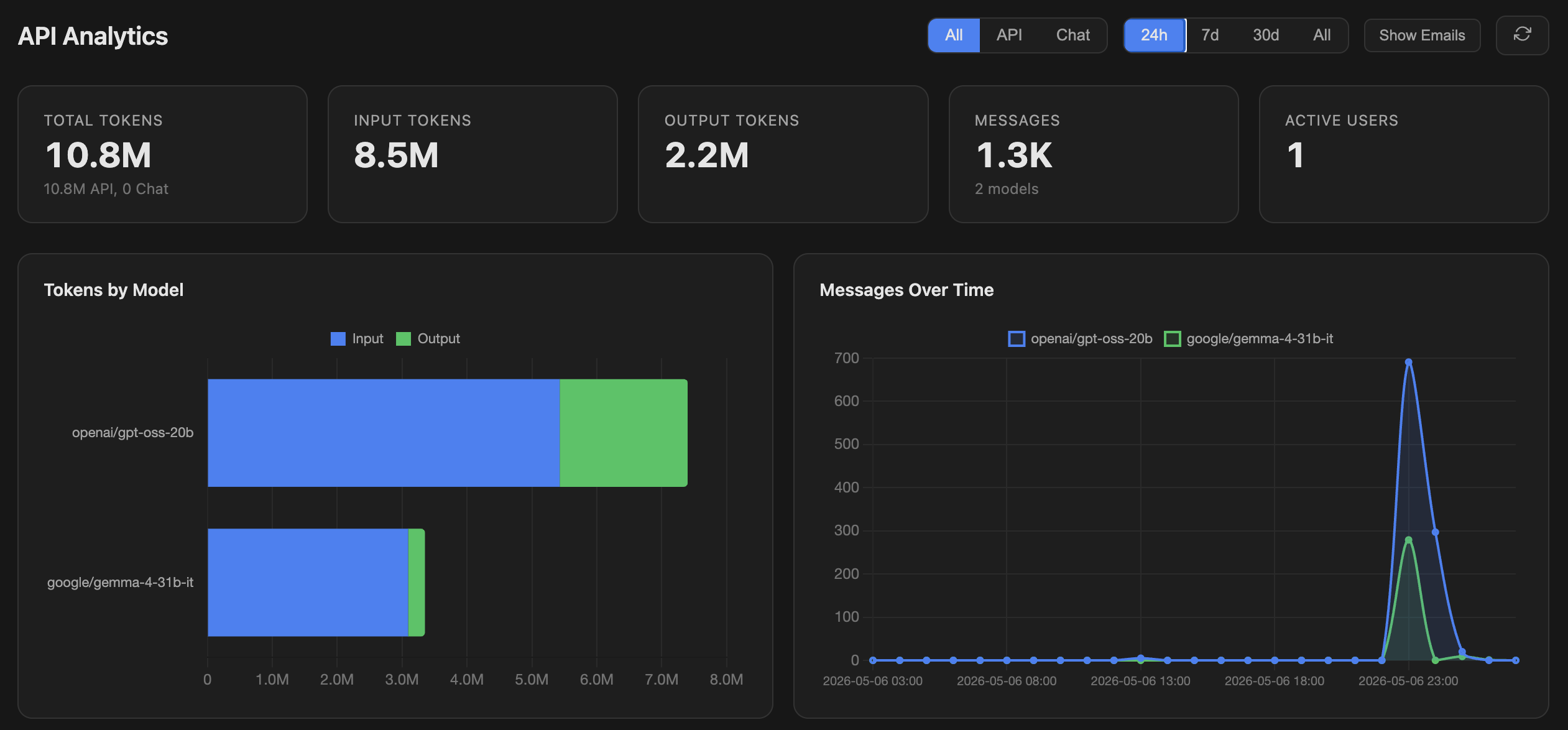 OpenWebUI’s OpenRouter view for this work, ~10.8M tokens, ~1.3K requests. One AISLE
OpenWebUI’s OpenRouter view for this work, ~10.8M tokens, ~1.3K requests. One AISLE scan.py pass over sys/rpc/ is ~700 of those. All of it, retries and dead ends included, ran about $12 on OpenRouter, and zero if you run the model locally.
Coming Up Next
I’ve got more coming on this, from a different angle. Stay tuned.
Reach out on X or mastadon if you have questions, and send the reproduction repo a ⭐️ if you find it useful.
Going Deeper with This Workflow


If this post made you want to build, scaffold, and break local AI pipelines against real targets, that’s exactly what Agentic RE: Automating Reverse Engineering & Vulnerability Research with AI covers, end to end. The course works the system-over-model thesis as a runnable artifact: AISLE’s three-stage pipeline on a model you control, detection measured as a rate rather than a single run, and your own system stages (like the reachability filter here) to cut the false positives. Plus reproducible agent workflows across Windows, Apple, Android, and other platforms. I’m teaching it in two formats:
- Virtual cohort, July 6-10 2026 — five half-days, live over Zoom: Agentic RE — CLEARSECLABS virtual
- DEF CON 34, August 10-11 2026 — two days in person, Las Vegas: Agentic RE @ DEF CON 34